

Vous n'êtes pas identifié(e).
Bonjour à tous.
J'ai une table contenant une colonne au format character varying() contenant deux différents formats (21/02/2014 09:56, 2014-02-27 15:05:00+00).
Je souhaiterais uniformiser ces dates en Timestamp With Time Zone mais pour cela il faudrait déjà que je puisse détecter les formats existants.
Comment puis-je requêter cela ?
Merci d'avance.
Geo-x
Bonjour @ tous.
Je cherche à ordonner les éléments suivants, à la façon d'un dictionnaire :

C'est à dire que dans ce cas j'aurais :
"dé"
"dé a"
"dé m"
"dé z"
"dép"
"dép a"
"dép m"
"dép z"
"départ"
"dépbrt"
"dépzrt"
Postgres me ressort l'ORDER BY de cette façon :

Comment puis-je faire ?
Merci
Ok merci, c'est ce qu'il me semblait.
Geo-x
Bonjour à tous.
J'ai une question d'architecture sur mes bases Postgres.
J'ai les tables suivantes :
Table A {ID / Libelle}
Table B {ID / Libelle}
Un lien est possible entre les deux tables car les identifiants (ID) peuvent être identiques.
Comme dois-je déclarer mes contraintes ? Actuellement j'ai déclaré des clés primaires sur chacune des tables, mais en vérité, elles sont aussi les clés étrangères l'une de l'autre, est-ce possible de déclarer ces ID clés primaires et étrangères ?
Merci.
Geo-x
Bonjour rjuju et merci de votre réponse !
Oui c'est tout à fait ça, j'ai bien une clé primaire basée sur (id_table_a, id_table_b), c'est bien ce qui me semblait que la solution bleue n'était pas forcément utile.
Merci beaucoup et bonnes fêtes de fin d'année.
Geo-x
Bonjour.
J'ai une question à laquelle je ne trouve pas de réponse dans la documentation.
J'ai un Postgres 9.6 et j'ai entre autre des tables de liaison. Je voulais savoir pour ces tables de liaison s'il était dans les habitudes/nécessaire/ou au contraire contre performant d'ajouter un identifiant unique :
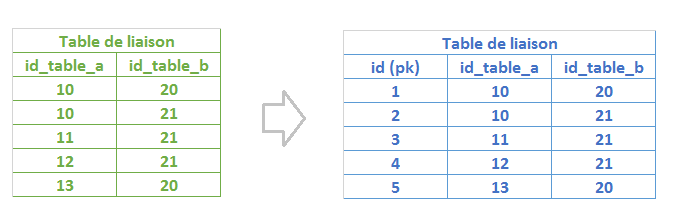
Merci de votre aide.
Geo-x
D'accord merci, ça répond à une bonne partie de ma question :-)
Bonjour.
Je rencontre des problèmes de timeout sur mes deadlocks lors d'une insertion massive de données (visiblement parce que le trigger en cours n'a pas terminé son travail) :
********************************************************************************
Message : ERROR: deadlock detected
Detail: Process 17067 waits for ShareLock on transaction 304743; blocked by process 17058.
Process 17058 waits for ShareLock on transaction 304747; blocked by process 17067.
Hint: See server log for query details.
Where: while locking tuple (59,65) in relation "intervention"J'ai donc souhaité modifier ma valeur max de deadlock_timeout dans le pg_hba.conf mais je vois que la valeur n'est pas renseignée (par conséquent j'en déduis que la valeur s'adapte au besoin) :
Nom deadlock_timeout
Valeurs
Valeurs autorisées 1-2147483647
Adaptabilité true
Source engine-default
Type d'application dynamic
Type de données integer
Description (ms) Sets the time to wait on a lock before checking for deadlock.Qu'est ce qui pourrait être à l'origine du problème ? Faut-il que je renseigne une valeur ?
Oui le NOT IN fonctionne, c'est juste que j'avais observé par le passé une meilleur performance avec le NOT EXISTS
Bonjour @ tous.
J'ai une table dans laquelle je souhaiterais conserver les 80000 derniers enregistrements (et donc supprimer quotidiennement tous les enregistrements < aux 80000 derniers enregistrements).
Pour cela je souhaite faire une requête du type :
DELETE FROM matable l WHERE NOT EXISTS (SELECT uuid FROM matable r WHERE l.uuid = r.uuid ORDER BY integration_date ASC LIMIT 80000)mais j'ai visiblement du mal à utiliser le NOT EXISTS puisqu'aucun enregistrement n'est pris en compte.
Avez-vous une idée sur comment reformuler cette requête ?
Merci de votre aide.
Geo-x
Bonjour @ tous.
J'ai du mal à comprendre la différence entre un OID et un UUID.
Pour le moment la seule différence que je vois c'est le format d'écriture de l'identifiant qui est différente, mais l'OID peut-il par exemple se substituer à l'UUID (sachant que l'OID est natif dans Postgres là ou l'UUID nécessite une extension).
Merci de vos éclairages.
Geo-x
Bonjour Michel et merci de votre retour.
Oui c'est bien comme cela que j'ai l'habitude de faire, comme indiqué ce que je souhaite c'est avoir des retours d'expérience sur cette méthode, ou bien s'il existe d'autres façons de faire auquel cas lesquelles ?
Geo-x
Et bien déjà félicitations pour votre livre, c'est très complet et très bien fait.
Pour essayer de compléter mes propos, l'objectif de cette futur base sera notamment de permettre à un utilisateur lambda d'accéder à des informations réunies sous forme de tableau (ex. tableau de gestion d'indicateurs) ou bien sous forme cartographique (ex. cartographie des documents d'urbanisme).
Par exemple si je prend ce MCD :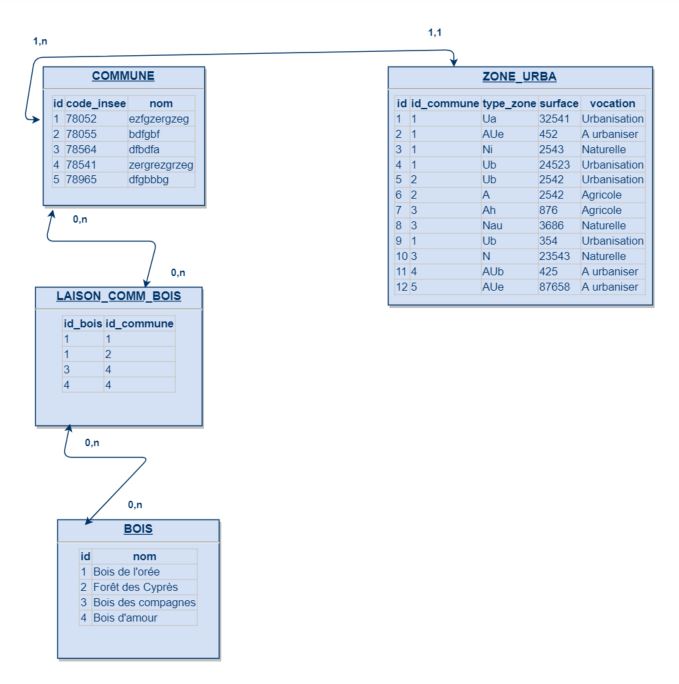
Je peux construire un tableau utilisable par un logiciel tiers :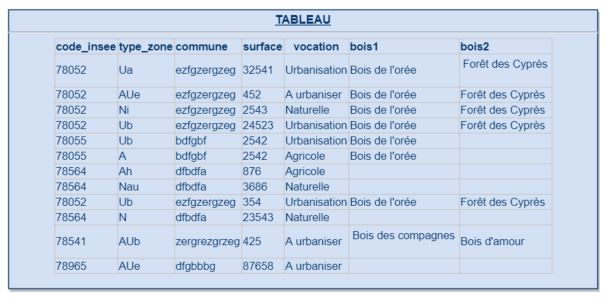
Problème si je souhaite que ce tableau soit modifiable si celui-ci est généré via une vue, comment puis-je faire ?
Geo-x
Bonjour @☺gleu et merci de votre réponse.
Pour le moment rien n'est définit en tant que tel puisque tout est à construire.
J'ai lu sur le bouquin PostgreSQL "Architecture et notions avancées" (je pense que c'est vous l'auteur ;-) ) que les vues permettant depuis la version 9.3 de mettre à jour directement les tables si la vue n'est pas construite à partir de jointure. Dans mon cas, étant donné que mon MCD sera plutôt réalisé "dans les règles de l'art" il sera plutôt aboutie mais inutilisable d'un point de vue logiciel.
Si je prend un exemple même très simple comme ceci :
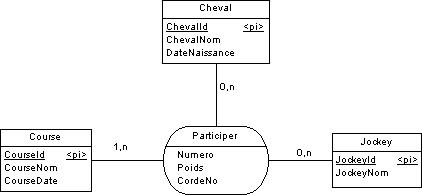
Et que mon logiciel utilise une table unique contenant le jockey, le cheval et la course, comment cela se passe ? j'imagine que mon cas n'est pas unique.
Geo-x
Bonjour @ tous.
J'ai une question d'architecture globale, je suis en train de construire un MCD propre avec liens, tables, clé, index et tutti quanti.
Le MCD en tant que tel n'est pas utilisable par le biais de logiciels tierces, alors ce que je souhaite faire, c'est créer des vues adaptée sur lesquelles l’utilisateur pourrait faire des modifs, de la visu etc...
J'utiliserais la dernière version de Postgres, et pour les vues, j'imagine, qu'étant donné qu'il y a des liaisons, je serai obligé de créer des règles.
Que pensez-vous de cette manière de procéder ? Quelles sont vos expériences sur cette façon de faire ?
Par avance merci de vos retours.
Geo-x
Bonjour @ tous.
J'ai une question qui me turlupine depuis un petit bout de temps et je ne sais pas vraiment s'il existe une réponse idéale, je souhaiterais avoir votre avis.
Admettons que j'ai deux tables avec les relations suivantes : Table1 < 1,n ---------- 1,n > Table2 (vous l'aurez compris il peut y avoir plusieurs Table2.ID associé à un ou plusieurs Table1.ID et inversement.
Dans ce cas, vaut-il mieux construire sa base en faisant :
Solution 1
Table1 (ID) Table2 (ID) TableLien1_2 (ID1,ID2)Quitte à reconstruire les jointures dans une vue
Solution 2
Table1 (ID,ID2_1,ID2_2,ID2_3)si on connait à l'avance le max ou
Table1 (ID,ID2_multi)par exemple en écrivant ID2_1;ID2_2;ID2_3
Solution 3 Autre solution que je ne connais pas
Qu'en pensez-vous ?
Geo-x
Le problème ne semble pas propre à QGis, j'ai déjà pu constater ce problème lorsque j'ai voulu faire une insertion dans une vue regroupant deux tables directement dans Postgres.
D'une manière générale, dans le RETURNING, lorsque vous souhaitez afficher : un champ caractère vide vous pouvez mettre :
'' AS monchamps'il s'agit d'un champ nombre vous pouvez mettre :
0 AS monchampdans les deux cas vous pouvez mettre :
NULL AS monchampSi je regarde votre exemple, votre INSERT ne concerne pas le champ 'type_cable', par conséquent, il faut que vous le déclariez dans le RETURNING au même titre que le champ 'nb_fo' avec :
NULL AS monchampou
'' AS monchampou
0 AS monchampselon le type de champ.
Je vous ai donné dans l'exemple un RETURNING en lien avec le code que vous m'aviez fourni, par conséquent, dans votre table complète, la colonne geom n'est pas en troisième position mais en dernière position.
Si vous appliquez tel quel l'exemple fournit, vous dites dans votre régle ce que votre vue doit afficher dans une 15aine de champs alors qu'il faudrait lui dire pour une 30aine (champs de votre table). Il faut, dans votre clause RETURNING, que vous disiez ce qu'il doit renvoyer au niveau de votre vue pour les lignes nouvellement insérées.
Exemple :
> Table :
champ1, champ2, champ3,champ4,champ5> Régle d'insertion :
INSERT INTO (champ1,champ3,champ5) VALUES (new.champ1,new.champ3,new.champ5) RETURNING champ1, '' AS champ2, champ3, 0 AS champ4,champ5Vous dites ainsi à votre vue ce qu'il faut qu'elle affiche pour ces lignes nouvellement insérées.
Concernant QGis, je ne sais pas s'il s'agit de l'évolution de Postgres qui inclut cette contrainte, ou si c'est celle de QGis...
Geo-x
Bonjour Girish.
Dans l'exemple évoqué plus haut, il s'agissait d'effectuer une insertion sur quelques champs de la table et non sur l'intégralité.
Afin que cette insertion puisse fonctionner, il fallait pouvoir "déclarer" l'intégralité des champs de la table d'où le RETURNING (...) appelant tous les champs de la table.
Donc pour répondre à votre question : Quels sont les champs renseignés dans la clause RETURNING ? > Tous les champs de votre table (ou de vos tables)
Cela donnera quelque chose du genre :
RETURNING id_cable, identifiant, geom, dms, commentaire, longueur, id_type_cable, id_nb_fo, id_role_fibre, id_type_fo, xlbl, ylbl, olbl, t_pol, c_pol, c_cad, cad_lbl, com, xlbl1, ylbl1, olbl1, id_etat, id_dossier, id_situation;Pour information, dans mon cas également il s'agissait d'un travail avec QGis :-)
Geo-x
Bonjour, c'est parfait jmarsac, merci beaucoup !
Bonjour @ tous.
Suite à un changement de version de PG Admin (V 1.22.2), dès que mon résultat de requête est trop long, le résultat est coupé par ceci : (...)
Ou puis-je modifier ce paramétrage ?
Par avance merci de votre aide.
Geo-x
Merci du retour jmarsac :-)
J'ai compris d’où venait le problème.
Comme indiqué ma vue reprend des champs de la table mais crée des colonnes supplémentaires en calculant des indicateurs.
La vue doit pouvoir afficher les colonnes concernant ces indicateurs, du coup il faut l'intégrer dnas le RETURNING même si ce sont des valeurs "fantômes" du genre
CREATE OR REPLACE RULE "_INSERT" AS
ON INSERT TO view_table DO INSTEAD INSERT INTO table (id, wkb_geometry, nom)
VALUES (new.id, new.wkb_geometry, new.nom)
RETURNING id, wkb_geometry, nom, 0::numeric AS indicateur1, 0::numeric AS indicateur2;Il est nécessaire d'utiliser la même technique, si la vue comporte également un ON UPDATE.
Geo-x
Bonjour Gleu.
J'utilise les triggers pour les tables uniquement mais pas pour les vues, je ne sais pas forcément comment les utiliser correctement.
Comment feriez-vous ?